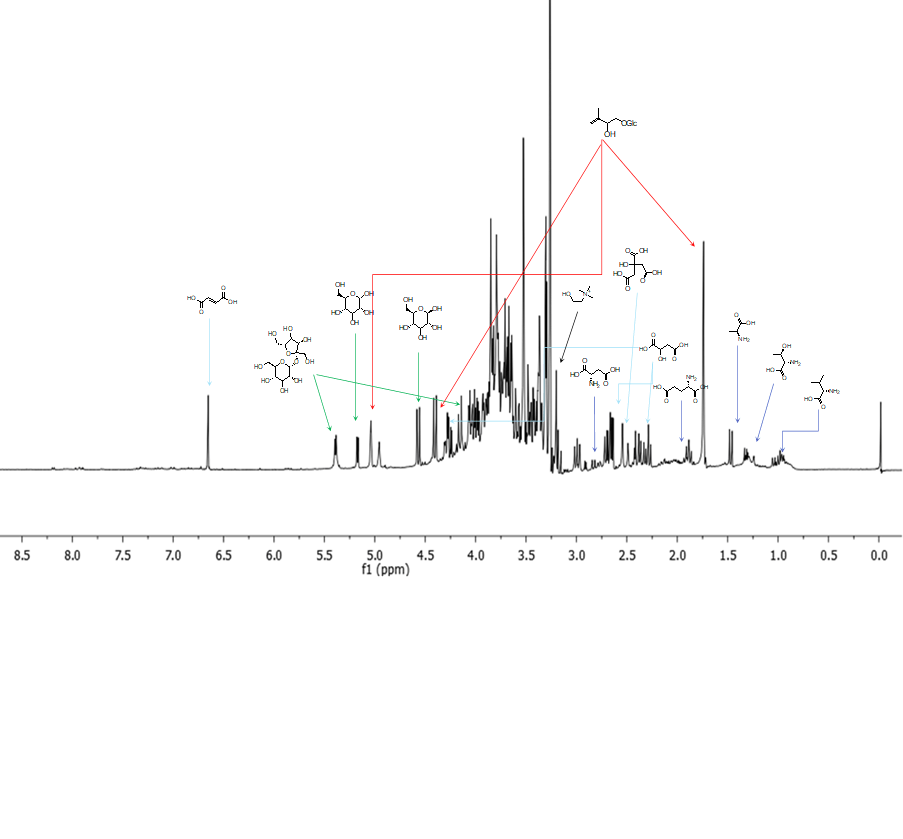
Nel corso della settimana scorsa si è tenuta la prima parte del laboratorio di Metabolomica.
Gli studenti del corso hanno preparato degli estratti e li hanno analizzati mediante NMR…ora la sfida è identificare quanti più metaboliti possibile prima della prossima esperienza di laboratorio in cui si misureranno con analisi statistica multivariata e 2D NMR!
La Spettroscopia di Risonanza Magnetica Nucleare (NMR) è una tecnica che non ha rivali nell’ambito della caratterizzazione strutturale. Questa tecnica spettroscopica, che sfrutta le proprietà magnetiche dei nuclei di alcuni atomi, ci permette di avere informazioni fondamentali sui composti organici. Non tutti i nuclei sono attivi all’NMR, ma tra quelli attivi si annoverano il protone e l’isotopo 13C del carbonio ed è proprio grazie all’applicazione a questi nuclei che otteniamo informazioni strutturali fondamentali per poter identificare la struttura dei composti.
Da uno spettro protonico possiamo dedurre numerose informazioni: il chemical shift ci dà informazioni su quello che è l’intorno chimico, la molteplicità ci dà informazioni sul numero di protoni legati ai carboni vicini (con le costanti di accoppiamento che ci forniscono altre importanti informazioni strutturali), infine l’integrazione ci permette di avere informazioni di tipo quantitativo. L’utilizzo di techinche 2D-NMR, inoltre, ci dà la possibilità di ricostruire l’intero scheletro delle molecole. Tutte queste potenzialità sono estremamente utili in metabolomica. Abbiamo visto (e vedremo) in che modo possiamo applicare questa tecnica all’analisi metabolomica.
Intanto, cerchiamo di capire meglio il principio di base su cui poggia questa potentissima tecnicha. Di seguito, due video che possono aiutarci. Il primo, prodotto dalla Bruker, il secondo da Sciencesketch.
Curiosi anche di sapere come è fatto lo strumento all’interno? Date un’occhiata qui!
Al link seguente è possibile scaricare il materiale di supporto allo studio:
Testi utili per ulteriori approfondimenti:
-D’Ischia “La chimica organica in laboratorio” Ed. Piccin -Hesse “Metodi Spettroscopici in Chimica Organica”
(entrambi disponibili in biblioteca; in caso di indisponibilità, rivolgersi alla docente)
NMR-based metabolomics
Dall’analisi NMR di un campione si possono dedurre tante informazioni diverse. Ma come si effettua un’analisi metabolomica mediante NMR?
A partire dal materiale liofilizzato, si ottengono gli estratti con una procedura molto semplice che prevede l’estrazione diretta in solventi deuterati (necessari per l’analisi NMR). Questi estratti vengono analizzati, ottenendo gli spettri, che saranno poi processati: questo processing prevede l’apodizzazione, la fasatura, la calibrazione rispetto allo standard intetno e la correzione della linea di base
A questo punto si procede con l’integrazione. Questa è effettuata attraverso il processo di bucketing o binnig: lo spettro si divide in tanti segmenti di lunghezza definita (in genere 0.02 o 0.04 ppm) e si procede ad integrare l’area sotto la curva di ogni bucket. Si ottiene in questo modo una matrice di dati in cui le osservazioni sono i singoli campioni analizzati e le variabili sono i vari bucket, che assumeranno quindi il valore dell’area per quella parte dello spettro in ciascun campione (NB: le aree sono in genere normalizzate rispetto allo standard interno a alla total intensity).
La matrice di dati così ottenuta è sottoposta ad analisi statistica multivariata. Questa sarà utile ad estrarre le informazioni significative dal nostro set di dati.
Una volta identificati i segnali NMR significativi per la nostra analisi, è necessario “tradurre” questi segnali in metaboliti. Si opera a questo punto per step successivi. Il primo passaggio è quello del confronto con la letteratura e con i database. A questo proposito, è necessario sottolineare come l’NMR sia una metodica altamente riproducibile. In ogni caso, se questa ricerca non ci dà la risposta sperata, si può optare per l’analisi NMR bidimensionale (2D NMR).I metodi 2D NMR più utilizzati in metabolomica sono brevemente descritti di seguito.
COSY (COrrelation SpecroscopY)
Esperimento 2D omocorrelato. Permette di rilevare correlazioni omonucleari 1H-1H tra protoni vicinali e geminali
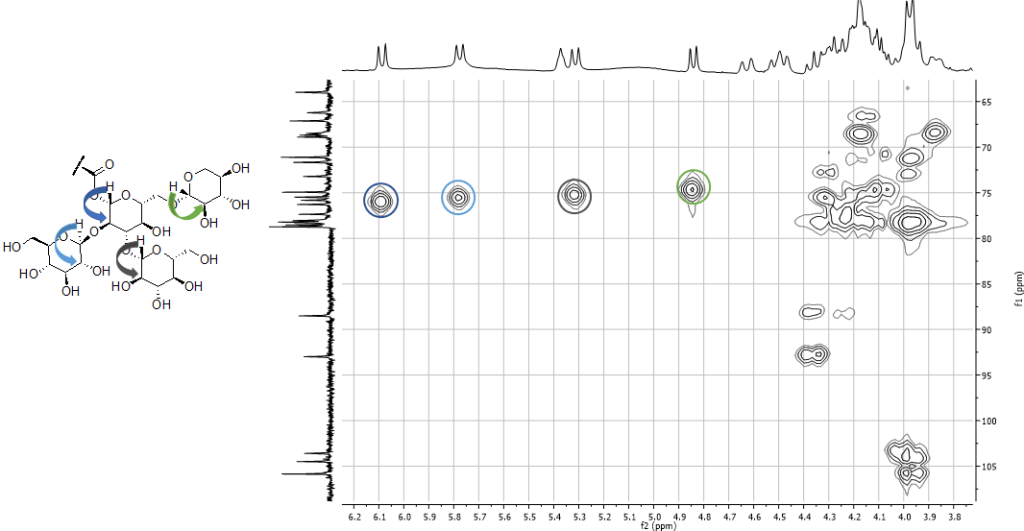
TOCSY (TOtal Correlation SpecroscopY)
Esperimento 2D omocorrelato. Permette di rilevare sistemi di spin (il trasferimento di magnetizzazione è interrotto da carboni quaternari).
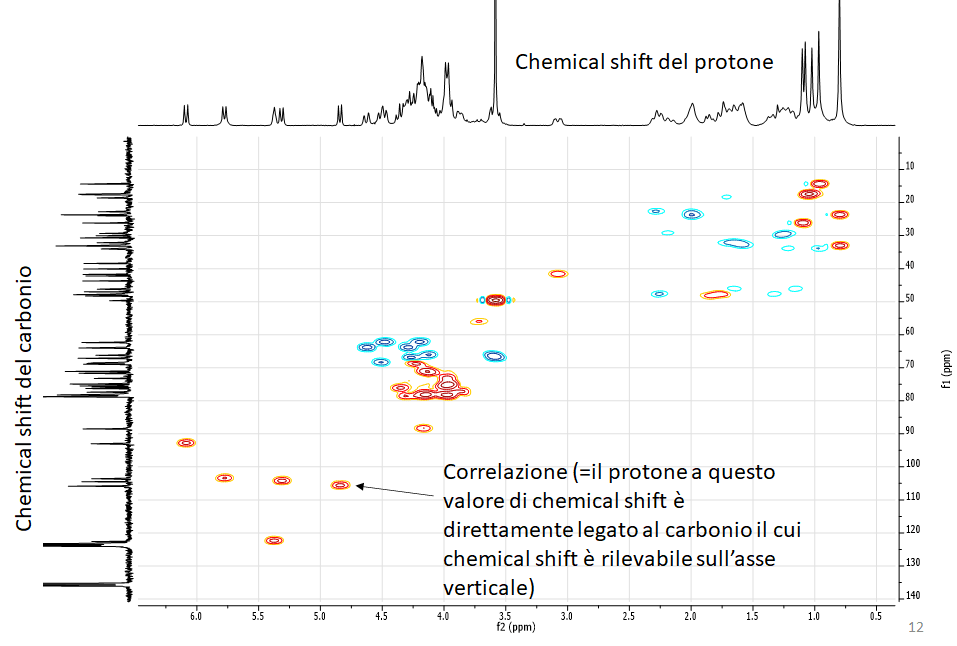
HSQC (Heteronuclear Single Quantum Coherence)
Esperimento 2D eterocorrelato. Permette di rilevare le correlazioni dirette protone-carbonio. Permette quindi di attribuire il valore di chemical shift del carbonio per ciascun carbonio protonato presente nell’estratto (o nella molecola, quando lo spettro si riferisce ad un composto puro)
H2BC (Heteronuclear 2 bond correlation)
Esperimento 2D eterocorrelato. Permette di rilevare le correlazioni tra un protone e il carboni vicinale, a patto che quest’ultimo sia protonato.
Correlazioni selezionate indicate sullo spettro e sulla struttura con lo stesso colore
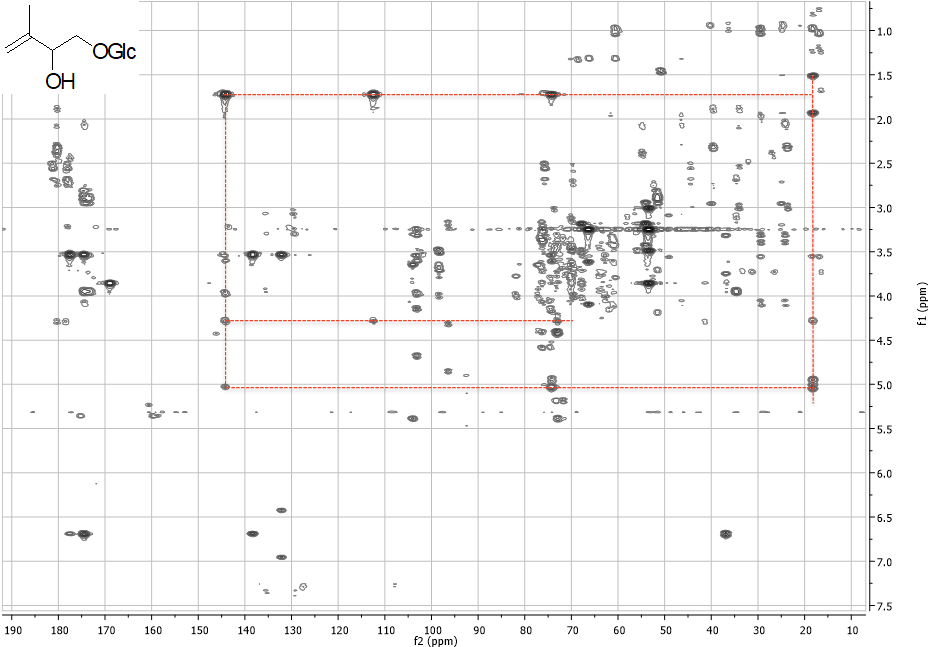
HMBC (Heteronuclear Multiple Bond Coherence)
Esperimento 2D eterocorrelato. Permette di rilevare le correlazioni tra un protone e carboni distanti due, tre o quattro legami. Un esperimento alternativo è noto come CIGAR-HMBC.
Sono evidenziate le correlazioni del composto mostrato in alto a sinistra. Le altre correlazioni appartengono ad altre componenti dell’estratto.
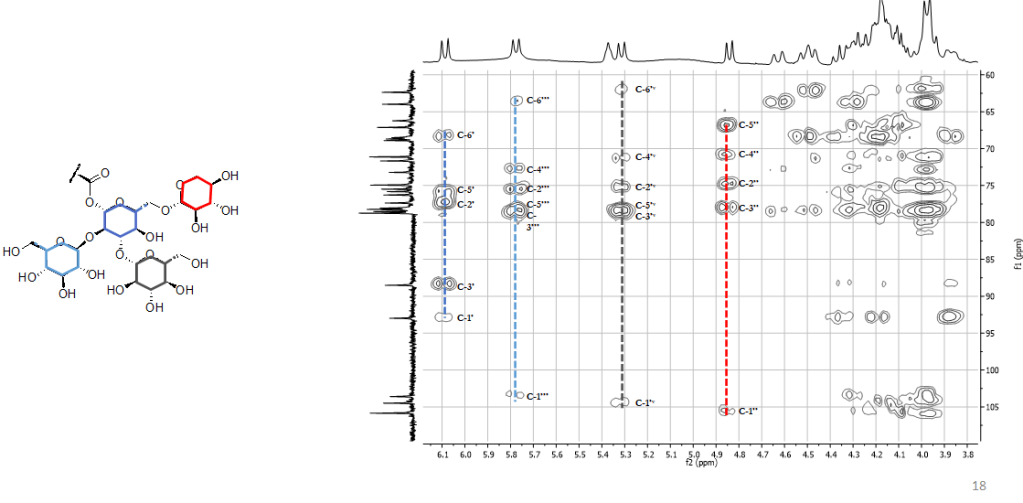
HSQC-TOCSY
Esperimento 2D eterocorrelato. Permette di rilevare sistemi di spin, che in questo caso includono sia i protoni sia i carboni.
Grazie alla combinazione delle informazioni che si ottengono dai diversi spettri 2D NMR, è possibile identificare i costituenti dell’estratto anche in miscela. Per metaboliti già noti, a questo punto sarà possibile confrontare i dati NMR con quelli riportati in letteratura o con quelli degli standard (a patto che siano acquisiti nello stesso solvente). Per i composti identificati per la prima volta, al fine di confermare la struttura, saranno necessari l’isolamento (che a questo punto sarà facilitato dalle informazioni preliminari in nostro possesso circa la struttura del composto) e la completa caratterizzazione strutturale mediante tecniche spettroscopiche. Va infine ricordato che oltre ad identificare i componenti dell’estratto, è anche possibile quantificarli dato che l’ 1H NMR è una tecnica quantitativa (se gli spettri sono acquisiti con determinati parametri) e che è sufficiente in questo caso utilizzare uno standard interno a concentrazione nota.
Le due tecniche più utilizzate ad oggi per acquisire i dati in metabolomica sono senza dubbio la spettrometria di massa (MS) e la spettroscopia di risononanza magnetica nucleare (NMR). La prima sfrutta la possibilità di generare e separare ioni in base al loro rapporto massa/carica. A lezione abbiamo visto che in realtà esistono tantissime applicazioni (ed “evoluzioni”) diverse di questa tecnica che la rendono particolarmente utile nell’analisi metabolomica. Il video seguente illustra, invece, il principio di base.
In una serie di video proposti dalla Waters, è possibile capire più a fondo il principio di funzionamente dell’ESI (Elettrospray ionization), che abbiamo visto essere insieme all’APCI e al MALDI (con tutte le variazioni sul tema viste a lezione) una delle tecniche di ionizzazione più diffuse quando la MS è utilizzata in metabolomica. Per quanto riguarda gli analizzatori, è possibile vedere come è fatto un quadrupolo. Inoltre, è possibile approfondire la problematica della formazione di addotti, della formazione di specie con carica multipla, nonchè la questione dei picchi isotopici. Infine, viene affrontata la questione importantissima della risoluzione.
L’alta risoluzione è, in effetti, fondamentale nell’analisi metabolomica e, come abbiamo visto, anche l’applicazione della MS/MS aggiunge notevoli vantaggi in termini di determinazione dell’identità delle molecole. Nel seguente video è possibile seguire gli ioni nel loro cammino nel caso di un esperimento LC-MS/MS
Le tecniche di HR-MS e MS/MS (o tandem MS) hanno notevolmente contribuito all’applicazione odierna di questa tecnica in campo metabolomico. Inoltre, non va dimenticata la possibilità offerta dalle tecniche di imaging da un lato e dall’applicazione di tecnologie ancora più avanzate dall’altro. Come non menzionare, allora, l’utilizzo della ion mobility mass spectrometry, che separa gli ioni non solo in base al rapporto massa/carica ma anche in funzione della loro grandezza e forma.
La prima esercitazione di laboratorio del corso di Metabolomica si terrà domani 26/11/2025 a partire dalle 14:30.
L’esercitazione, destinata ai soli studenti che seguono il corso, consisterà nell’estrazione e analisi mediante metabolomica basata sull’NMR di campioni di origine vegetale.
Che cos’è la metabolomica? Come si colloca nell’ambito della biologia dei sistemi? Quali sono le possibili applicazioni? Qual è la tipica sequenza sperimentale di un approccio metabolomico? Questi sono alcuni dei punti trattati nel corso della prima lezione.
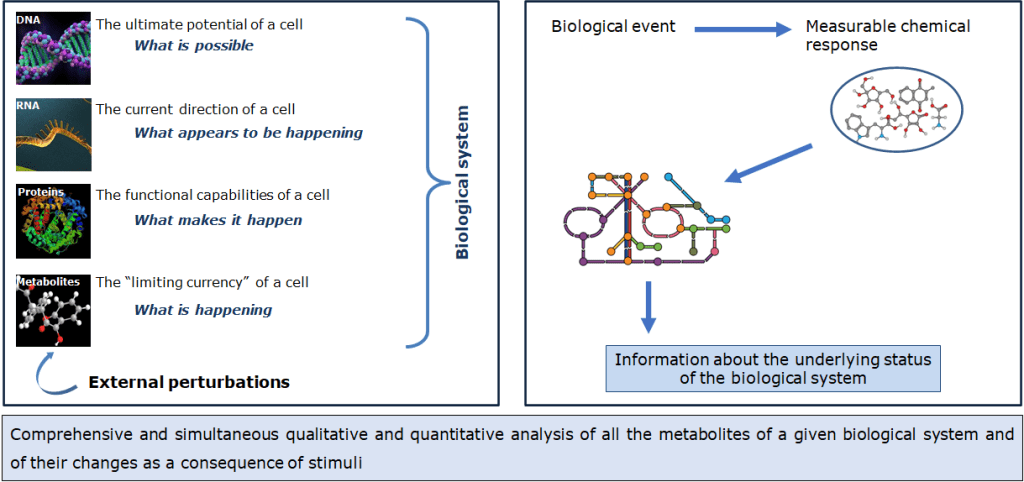
Metabolomica: un approccio all’interfaccia tra la chimica e la biologia
La METABOLOMICA è un approccio innovativo allo studio dei fenomeni e dei sistemi biologici.
Innanzitutto, dobbiamo considerare l’ampio range di applicazioni di questo approccio allo studio dei sistemi biologici. Applicazioni che riguardano la chimica delle sostanze naturali, la chimica degli alimenti, la chimica farmaceutica, il metabolismo, la fisiologia e lo studio della risposta a stress da parte degli organismi e delle interazioni che tra essi intercorrono, la chimica ambientale, la ricerca biomedica e tantissimi altri campi.
Del resto, la metabolomica si colloca all’interfaccia tra la chimica e la biologia, in quanto ciascun fenomeno biologico produrrà una risposta chimica misurabile e la determinazione delle variazioni osservate fornirà informazioni sullo stato del sistema biologico in analisi. Inoltre, andando a misurare quelli che sono i prodotti finali dell’espressione genica, ossia i metaboliti, fornisce informazioni essenziali su quello che è il fenotipo e la relazione di quest’ultimo col genotipo.
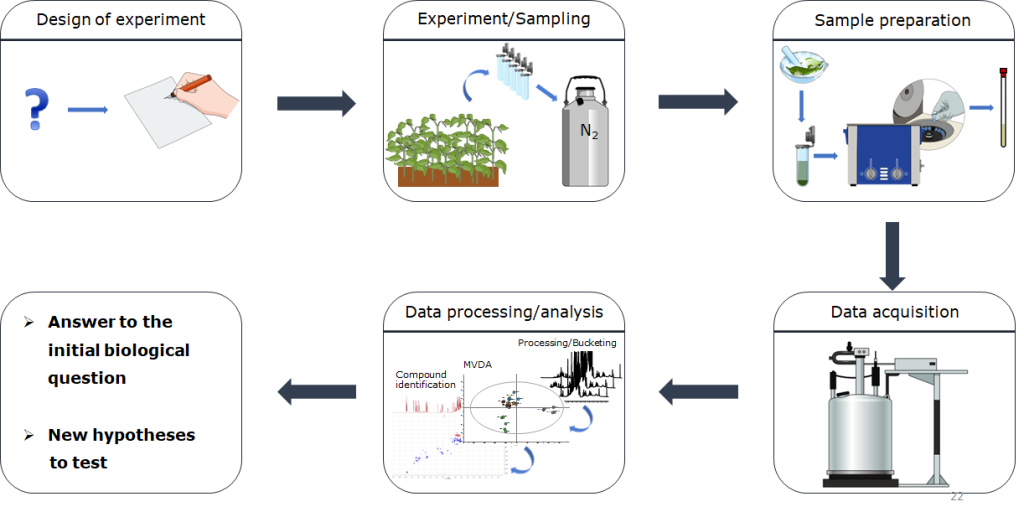
Uno step fondamentale nell’approccio metabolomico è la fase di disegno sperimentale. Al fine di ottenere dati che siano statisticamente e biologicamente significativi e che diano risposta alla nostra research question, è necessario definire a priori tutti i parametri sperimentali da considerare, le variabili da valutare e quelle da controllare. Sarà necessario inoltre prendere in considerazione l’utilizzo di un numero opportuno di replicati tecnici e biologici (tale numero varia sia in base al sistema biologico in analisi, sia in base alle tecniche analitiche utilizzate).
A questo punto, sarà necessario procedere all’esecuzione dell’esperimento e/o al campionamento. Le metodiche utilizzate variano a seconda del tipo di campione, ma un punto fondamentale e ineludibile, al fine di ottenere risultati che rispecchino il reale stato del sistema, è il quenching del metabolismo: sarà necessario bloccare tutte le reazioni, siano esse catalizzate da enzimi o meno. In genere, questo si ottiene con il metodo del deep freezing, congelando il campione immediatamente in azoto liquido (-196°C). I campioni sono poi conservati a -80°C fino al momento della liofilizzazione. Quest’ultimo processo, che allontana l’acqua dal campione, è necessario sia per una migliore conservazione (l’acqua è il mezzo per la maggior parte delle reazioni che avvengono nei campioni biologici) sia (in alcuni casi) per rendere compatibile il campione con le successive analisi.
La maggior parte delle tecniche analitiche usate in metabolomica richiede che il campione sia in soluzione, di conseguenza il passaggio successivo consisterà in una procedura di estrazione dei metaboliti. In questo caso le metodiche variano sia in base alla natura del campione, sia in base alla piattaforma analitica che si utilizzerà nella fase successiva. Fase successiva che consiste nell’analisi della composizione chimica degli estratti. Diverse tecniche sono disponibili, ma quelle più comunemente utilizzate in metabolomica sono la Spettroscopia di Risonanza Magnetica Nucleare (NMR) e la Spettrometria di Massa (MS). Quest’ultima richiede solitamente una separazione a monte dei metaboliti che compongono l’estratto ed è quindi in genere interfacciata con un sistema cromatografico (GC o HPLC/UPLC).
Una volta acquisiti i dati, il complesso dataset ottenuto è analizzato attraverso metodiche di analisi statistica multivariata (MVDA) al fine di estrarre le informazioni circa la classificazione dei campioni e circa i segnali e, in ultima analisi, i composti responsabili della classificazione osservata. A questo punto, si procede con la caratterizzazione strutturale dei composti che risultano essere significativi nell’analisi. Questa caratterizzazione si avvale, tra l’altro, di tecniche ad alta risoluzione e di spettrometria tandem, nel caso della MS. Nel caso dell’NMR una caratterizzazione dei metaboliti nell’estratto è possibile mediante l’utilizzo di tecniche NMR bidimensionali. Per entrambe le tecniche, un supporto notevole è fornito dai database.
Le informazioni estrapolate mediante MVDA vanno poi integrate con le conoscenze sul sistema biologico in analisi e forniranno la risposta alla domanda che sottende lo studio o forniranno nuove ipotesi da testare.
Al seguente link è possibile scaricare le slide del corso, insieme a del materiale utile per approfondimenti.
Inolre, è possibile ottenere informazioni anche al seguente link: Introduzione alla metabolomica (contenuti: definizione di metaboloma e metabolomica, note sull’importanza di questo tipo di approccio e campi di applicazione, panoramica di quello che è l’approccio dal punto di vista metodologico).
E alla fine potrai anche testare le tue conoscenze
Il 16 e 17 ottobre 2025 si terrà presso il Polo scientifico dell’Università degli Studi della Campania “Luigi Vanvitelli” il 1st Emerging Trends in Biomolecular Sciences, evento centrale dei PhD Days 2025. Di seguito la locandina e il link al sito web dell’evento: https://phdays25.wordpress.com/
Tutti gli studenti del DiSTABiF sono invitati a partecipare!
Nel corso del PhDays, i dottorandi illustreranno e discuteranno con i loro colleghi e con i docenti e ricercatori i progressi fatti nel corso della loro attività di ricerca. Si tratta di un momento cruciale per loro, ma che può essere interessante anche per tutti gli studenti, soprattutto coloro che sono iscritti ai Corsi di Laurea Magistrale o agli ultimi anni del Corso di Laurea in Farmacia.
Ascoltando le relazioni dei dottorandi, potrete avere un’idea di quella che è l’attività di ricerca svolta presso il nostro Dipartimento. Tra l’altro, presto vi troverete di fronte a scelte importanti e potrebbe essere interessante capire, grazie al confronto con i vostri colleghi più grandi, se ad esempio l’attività di ricerca possa essere per voi una via percorribile. Inoltre, molto spesso non abbiamo ben chiaro neppure cosa sia il dottorato di ricerca: quale occasione migliore per confrontarsi con chi lo vive? Anche i docenti saranno presenti e sicuramente aperti a rispondere a qualsiasi vostra domanda (durante e dopo l’evento).
Infine, a breve probabilmente vi troverete nella condizione di scegliere in quale laboratorio svolgere la vostra attività di tesi. Questo punto è importante soprattutto per coloro che devono fare una tesi sperimentale o metodologica, per le quali è necessario frequentare un laboratorio. Molto spesso la scelta viene fatta con poca consapevolezza, magari puntando al “minimo sforzo, massima resa”, oppure si sceglie semplicemente seguendo il consiglio degli altri…o, ancora peggio, sentendosi obbligati dall’invito di un docente a fare la tesi nel proprio laboratorio. Perchè non fare una scelta più consapevole, basata su un reale interesse verso l’attività di ricerca? Il PhDays è una finestra aperta sul dipartimento, che vi permette di avere almeno un’idea di cosa si fa in diversi laboratori del DiSTABiF.
Sul sito dell’evento è disponibile anche il programma dettagliato dell’evento: https://phdays25.wordpress.com/program/, che si concluderà con un momento conviviale.
La METABOLOMICA è un approccio allo studio dei fenomeni e dei sistemi biologici che negli ultimi anni trova sempre maggiori applicazioni in diversi settori: dal campo biologico a quello alimentare, dal campo biomedico a quello ambientale, ecc. Questo approccio consiste nello studio dell’insieme dei metaboliti in un sistema biologico.
Il nostro Dipartimento offre un corso introduttivo su questo approccio innovativo e multidisciplinare. Il corso si propone di fornire agli studenti un’introduzione alla metabolomica e alle tecniche utilizzate. Le conoscenze e competenze acquisite potranno essere utili al laureato in Biologia in virtù del sempre più ampio utilizzo di questo approccio in diversi campi.
Oltre alle lezioni frontali sarà possibile partecipare anche a delle ESERCITAZIONI PRATICHE in laboratorio!
Ad inizio ottobre si terrà un incontro preliminare di presentazione del CORSO DI METABOLOMICA (insegnamento a scelta – CdLM in Biologia). La data, l’orario e il luogo di questo incontro saranno comunicati successivamente. Nel corso dell’incontro sarà illustrato il programma del corso e sarà definito anche l’orario delle lezioni e delle esercitazioni (NB: l’orario che sarà a breve pubblicato sul sito non è quello definitivo, in quanto il corso sarà organizzato in modo da venire quanto più possibile incontro alle esigenze degli studenti). La docente sarà a disposizione anche per rispondere ad eventuali domande/dubbi.
Gli studenti potenzialmente interessati al corso potranno registrarsi utilizzando il seguente link: Incontro introduttivo corso di METABOLOMICA.NB: la registrazione all’incontro informativo NON è assolutamente vincolante, così come la partecipazione all’incontro informativo non è vincolante per il corso stesso.
La partecipazione all’incontro è importante soprattutto per coloro che sono in dubbio sulla scelta del corso o che non hanno chiaro il concetto stesso di metabolomica, in quanto potranno porre tutte le domande necessarie per risolvere i dubbi in una direzione o nell’altra.
Sono invitati a partecipare tutti gli studenti (anche iscritti ad altri corsi di Laurea Magistrale) interessati al corso.
Ulteriori informazioni sono disponibili ai seguenti link: Syllabus























You must be logged in to post a comment.