CdLM Biologia Chimica Bioorganica
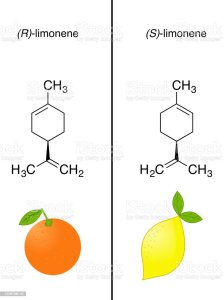
Materiale didattico relativo alla biosintesi e bioattività di monoterpeni e diterpeni
Università degli Studi della Campania "Luigi Vanvitelli"
Materiale didattico relativo alla biosintesi e bioattività di monoterpeni e diterpeni
Materiale didattico relativo alla biosintesi e bioattività di Eritromicine, Cannabinoidi, Alfatossine

Materiale didattico
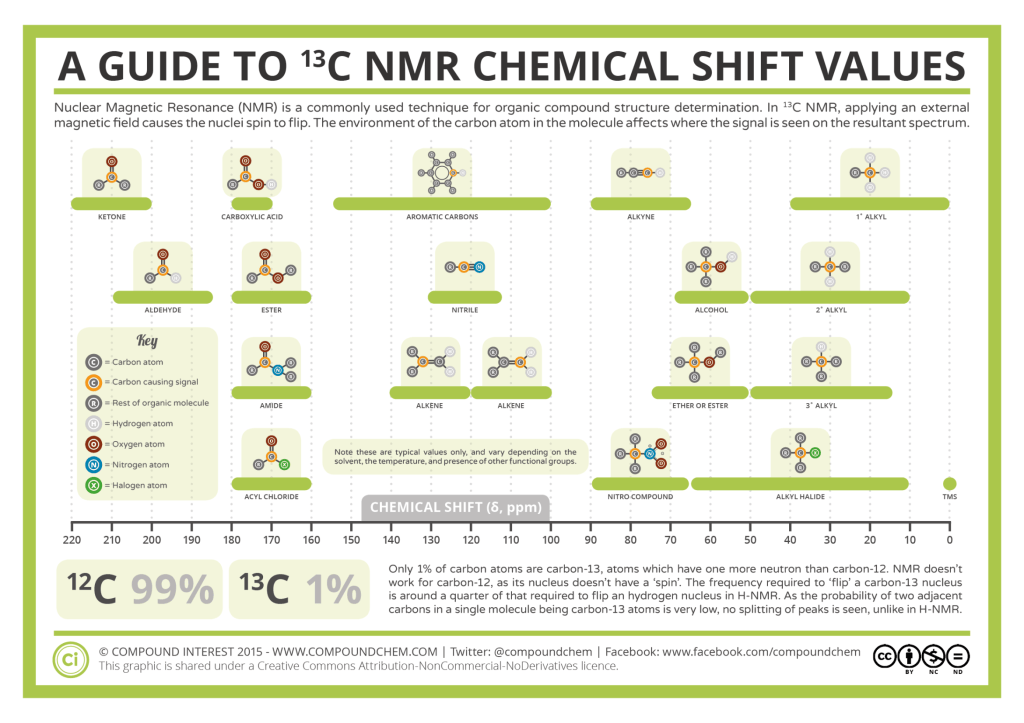

Spettroscopia 13C NMR
Spettrometria di massa

determinazione strutturale di molecole organiche mediante spettri combinati
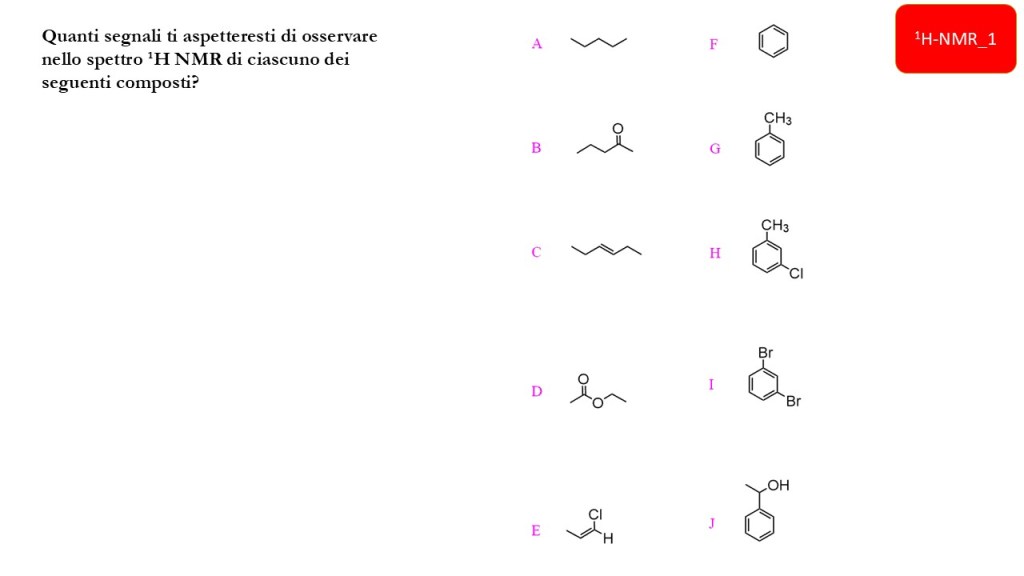
1H-NMR: chemical shift e forma del segnale
Di seguito il materiale didattico relativo all’argomento in oggetto ed un set di esercizi
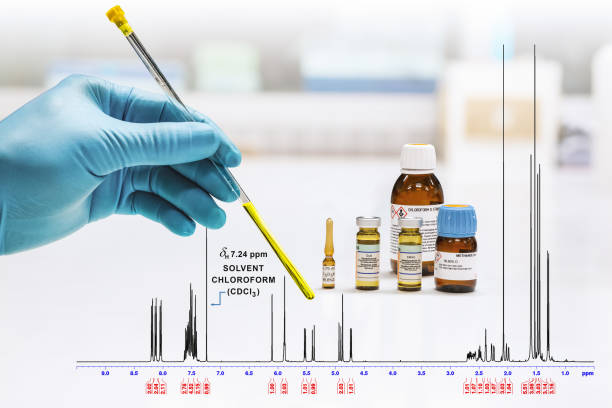
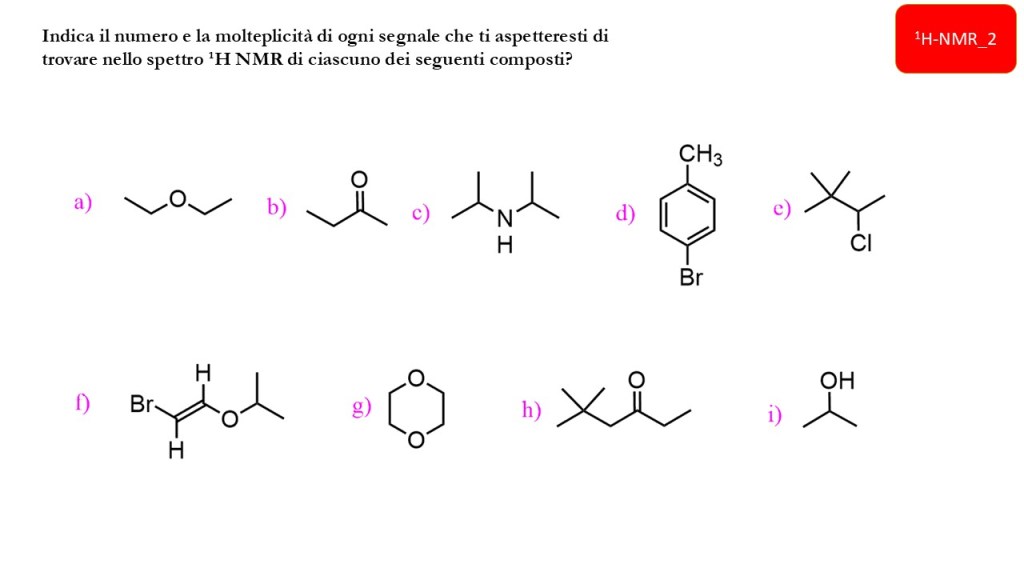
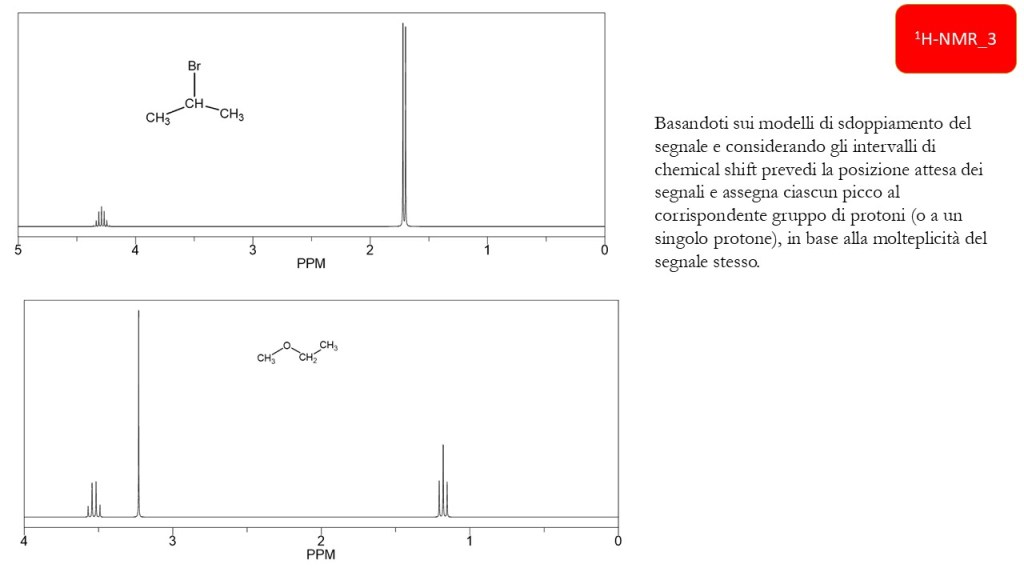
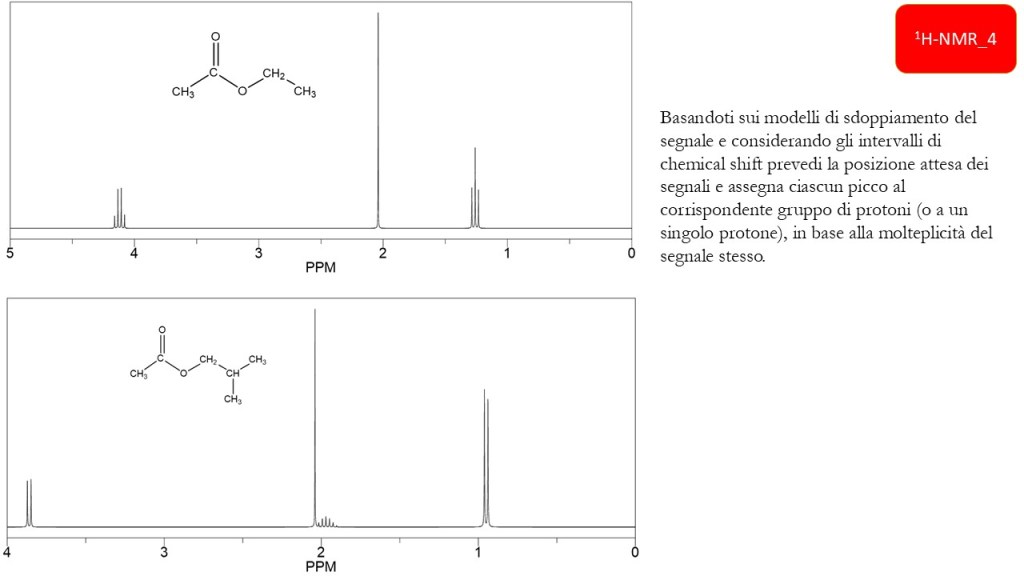
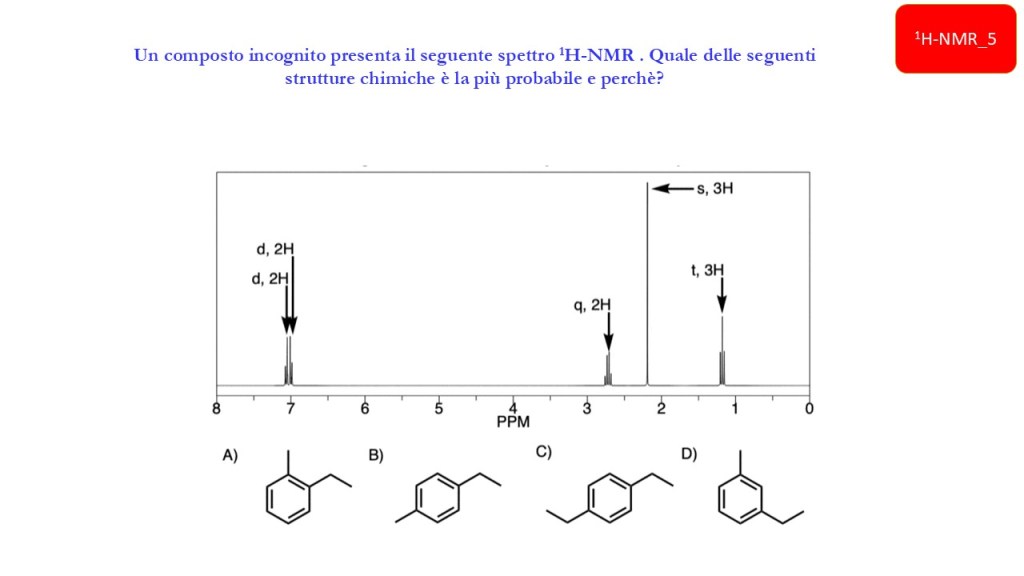
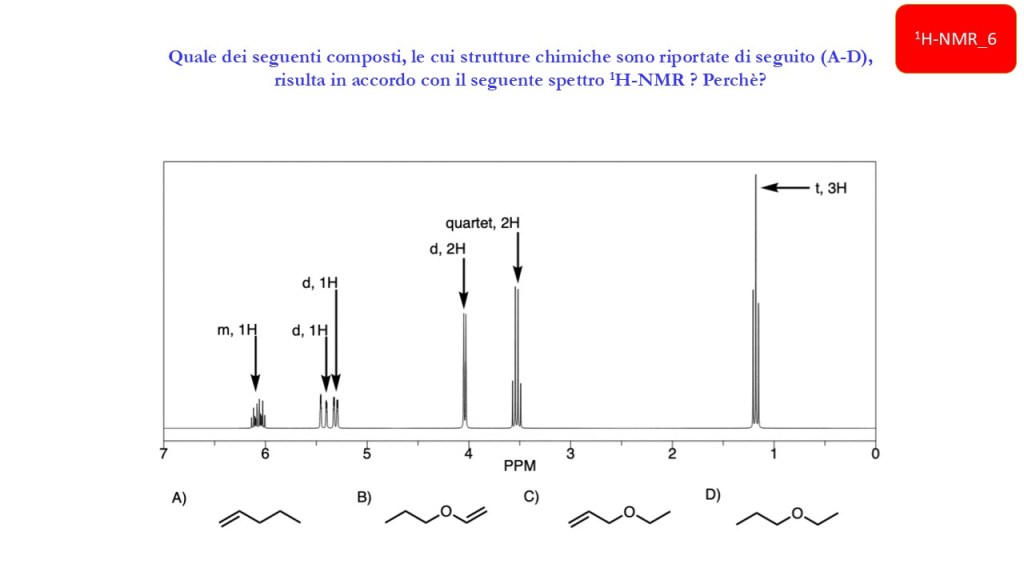
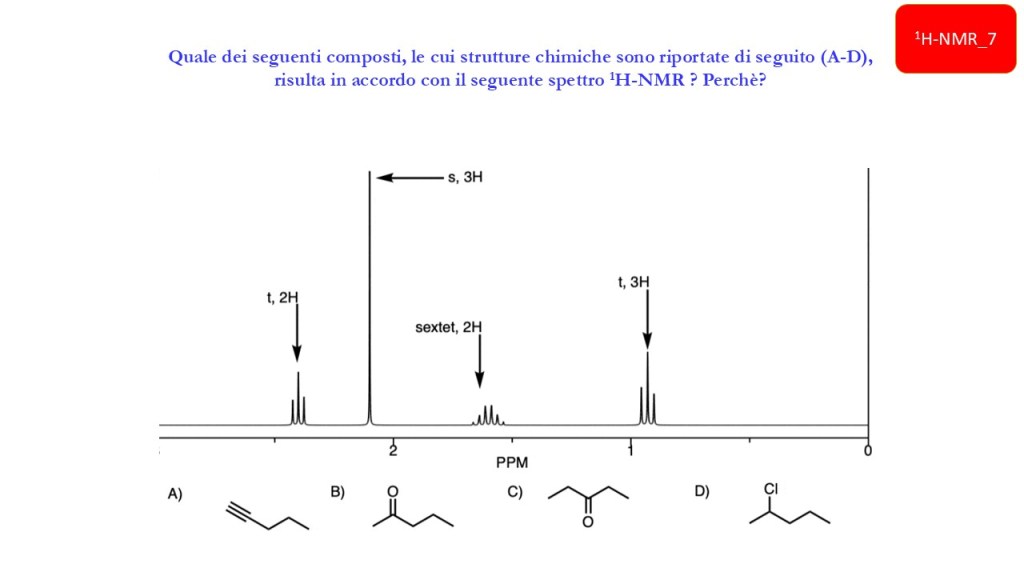
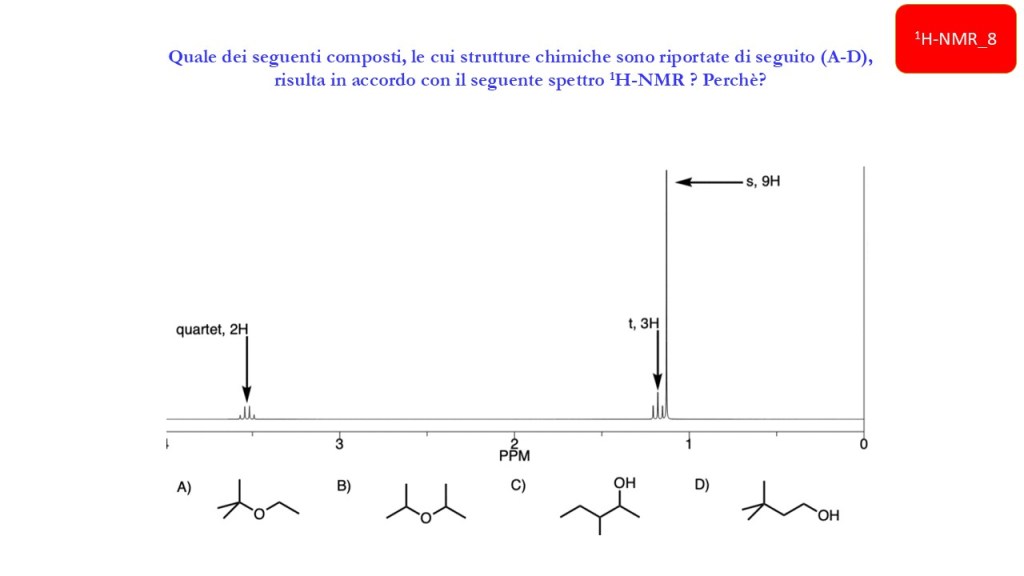
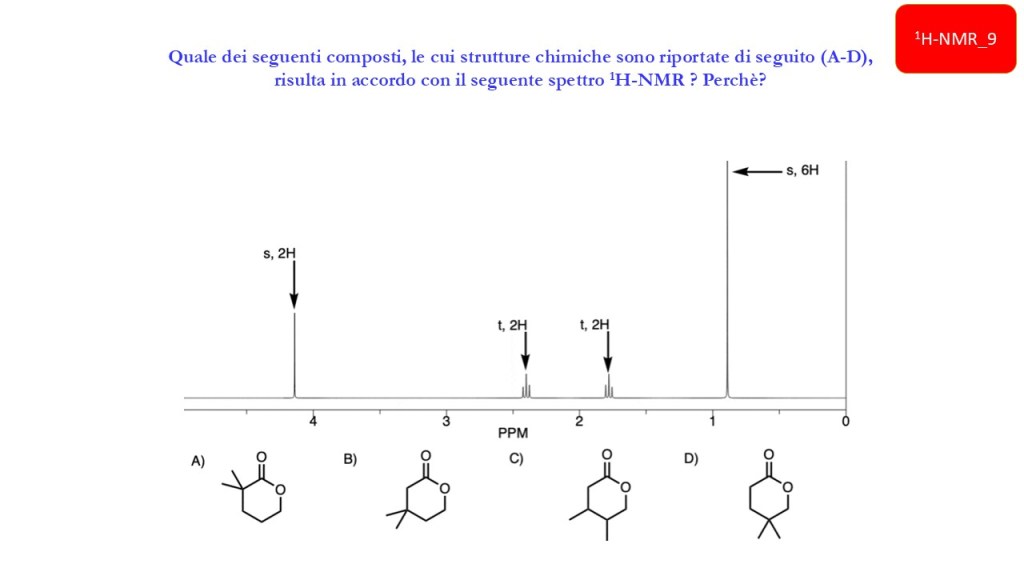
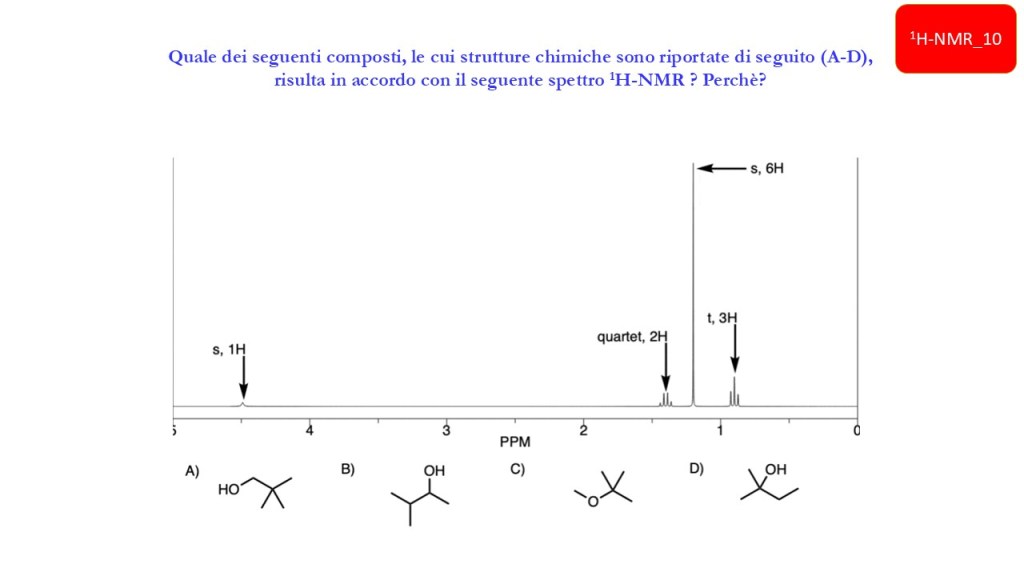
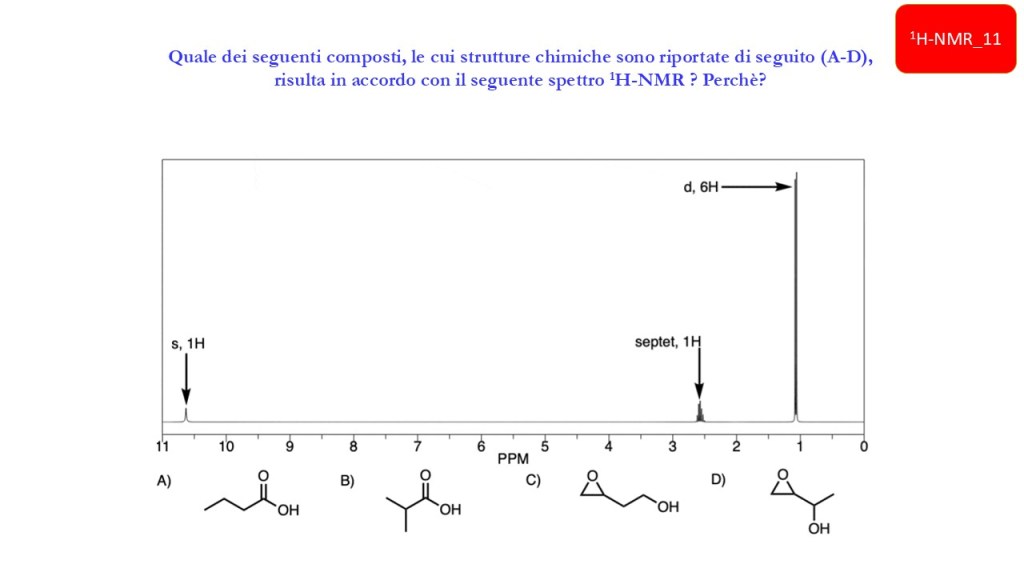
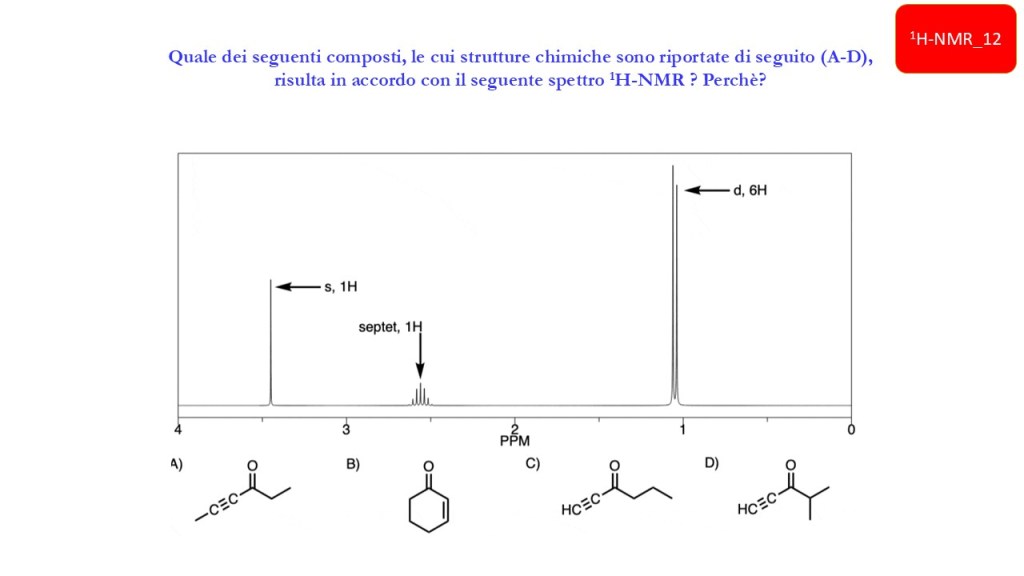
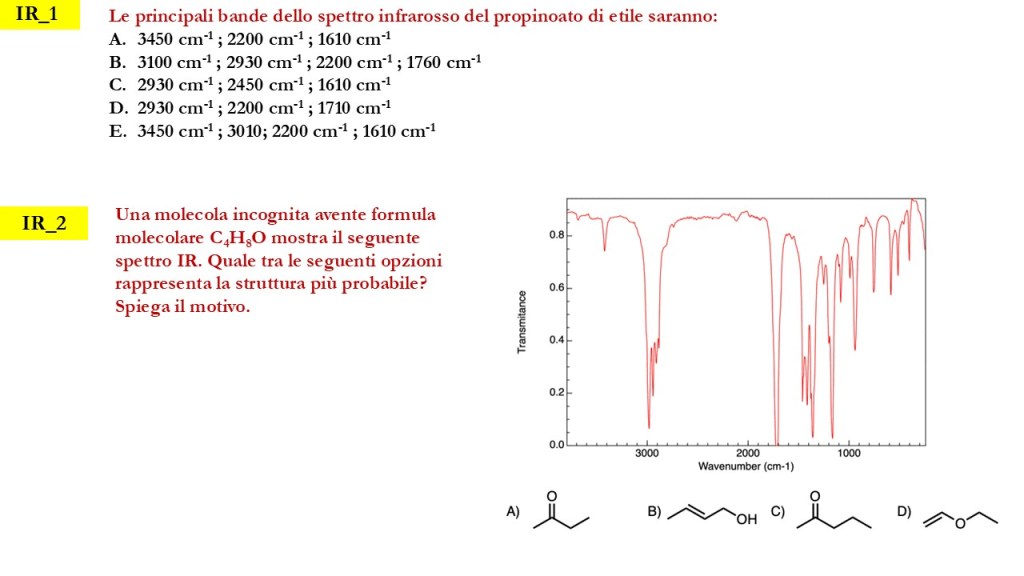
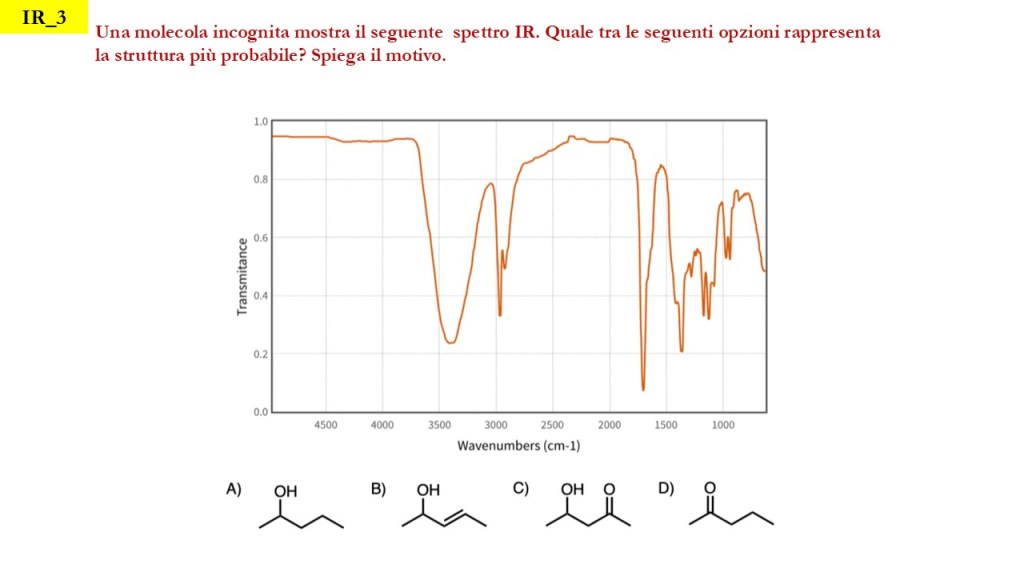
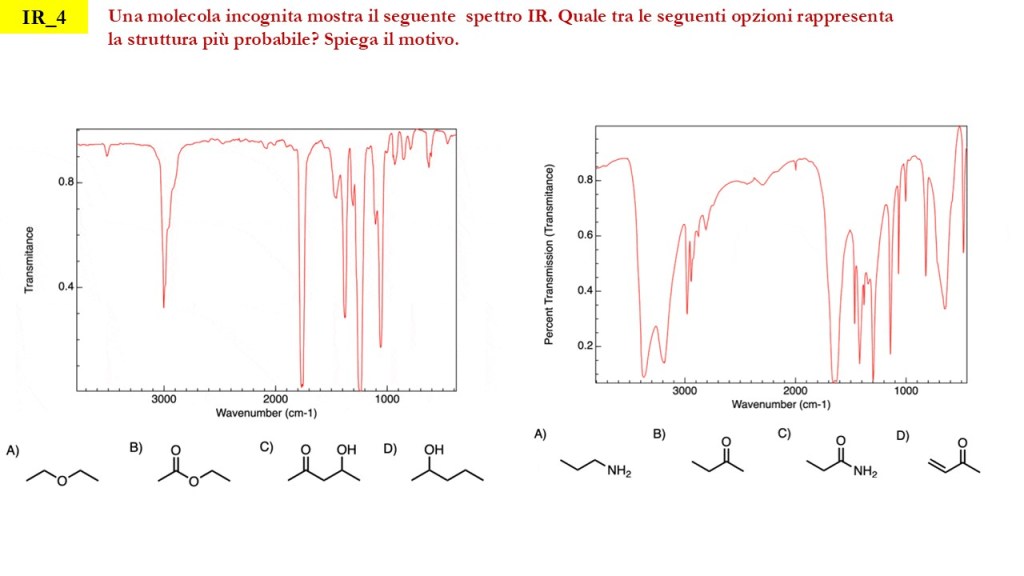
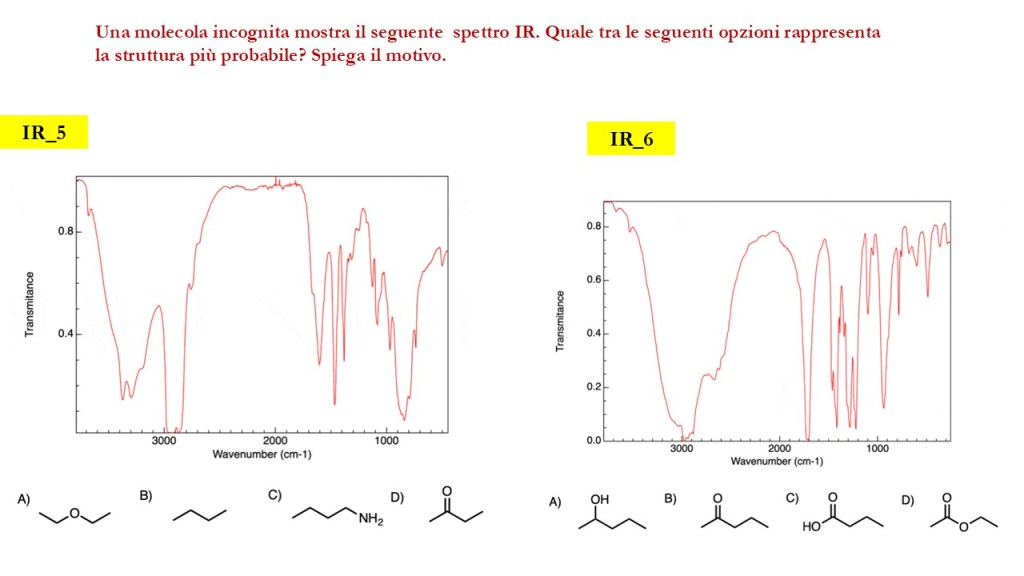
Esercizi Spettroscopia IR
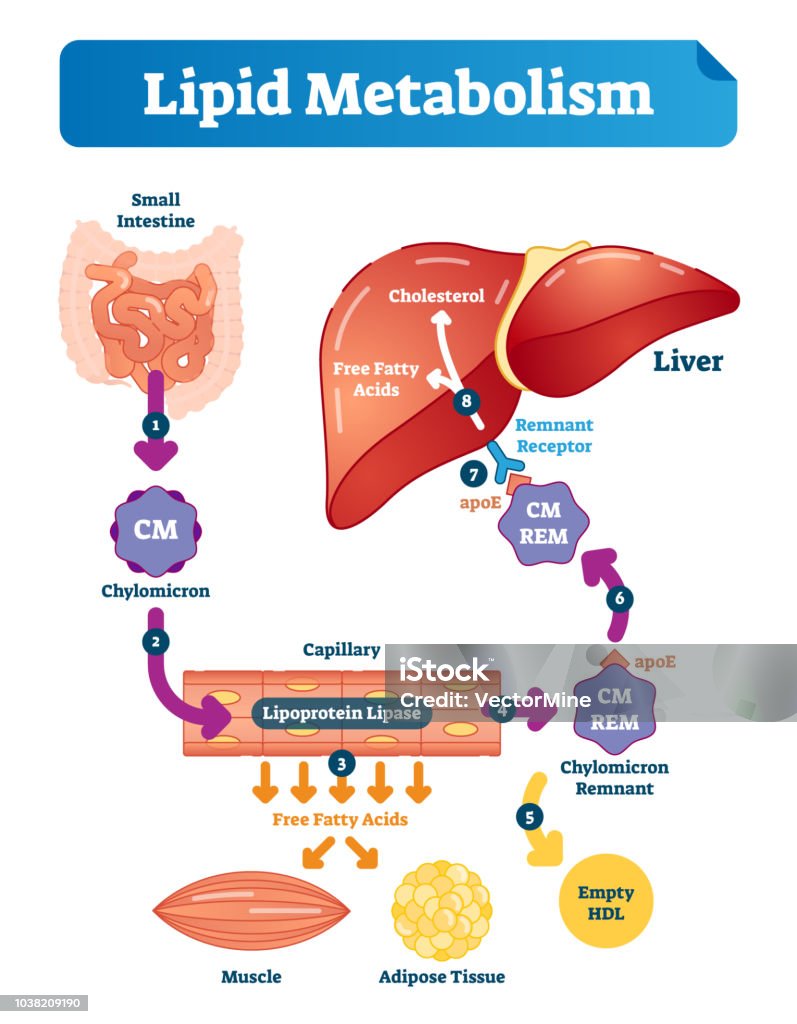
Materiale didattico Metabolismo dei lipidi
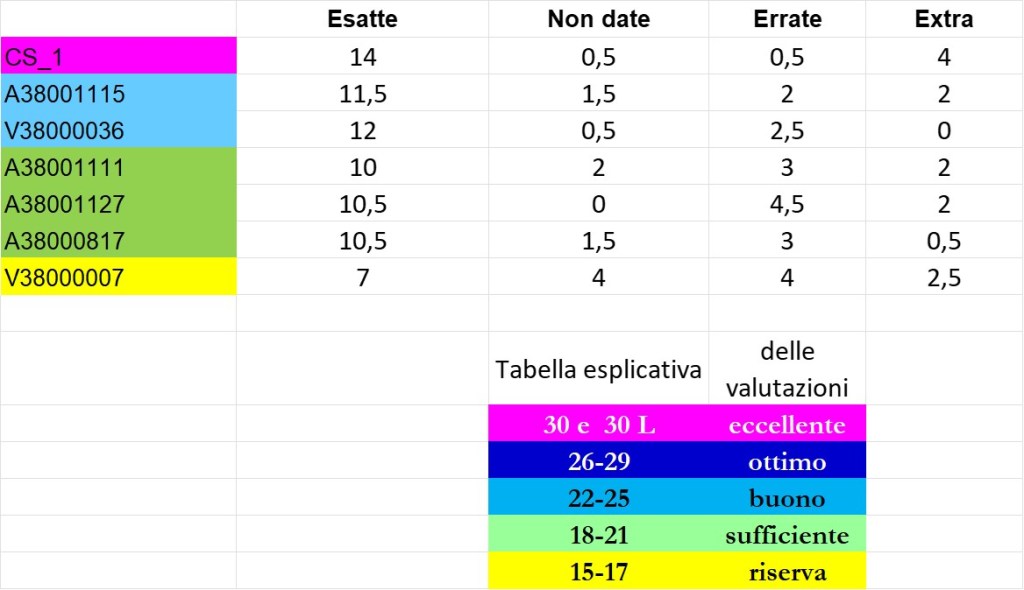
Gli interessati possono visionare il proprio elaborato domani 23 marzo 2026 al termine della lezione. Di avvisano inoltre gli studenti che la seconda prova intercorso si terrà mercoledi 25 Marzo 2026 alle ore 15. L’aula sarà comunicata domani a lezione
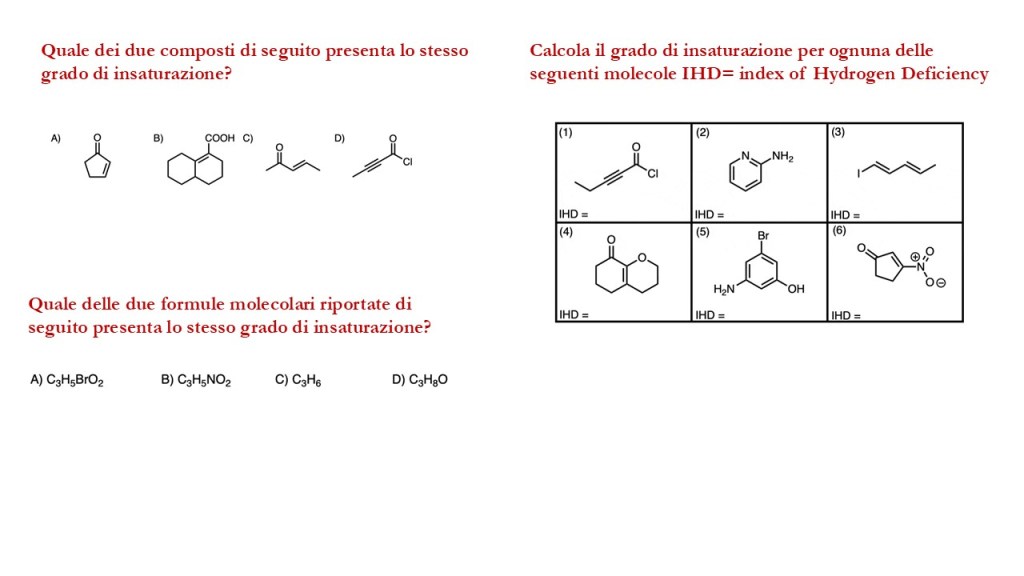
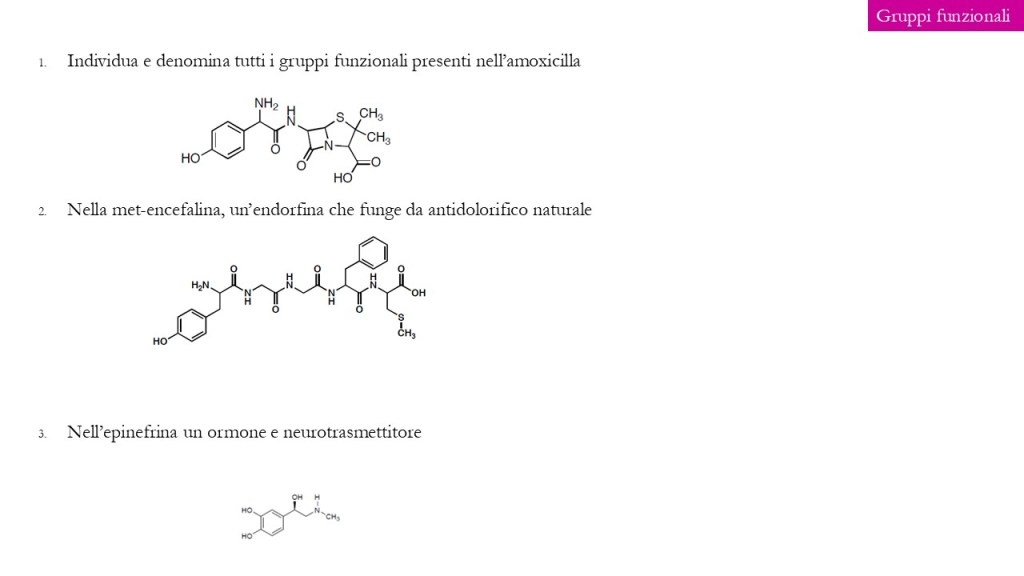
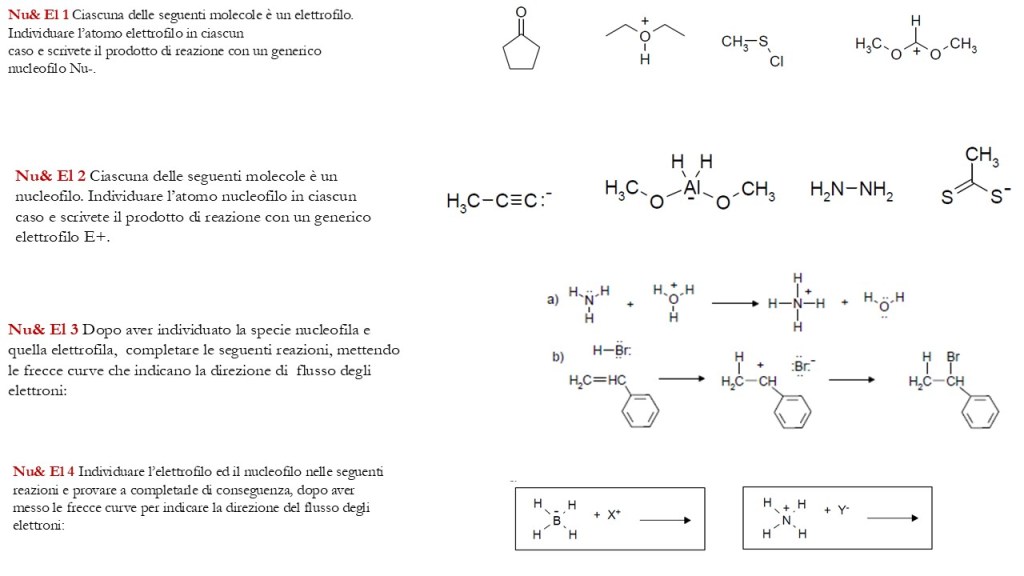
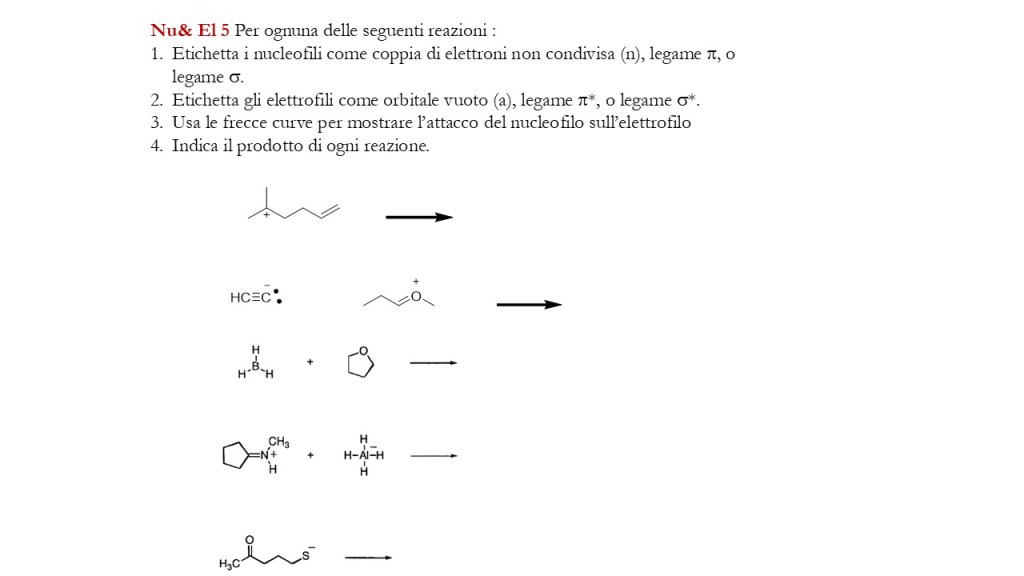
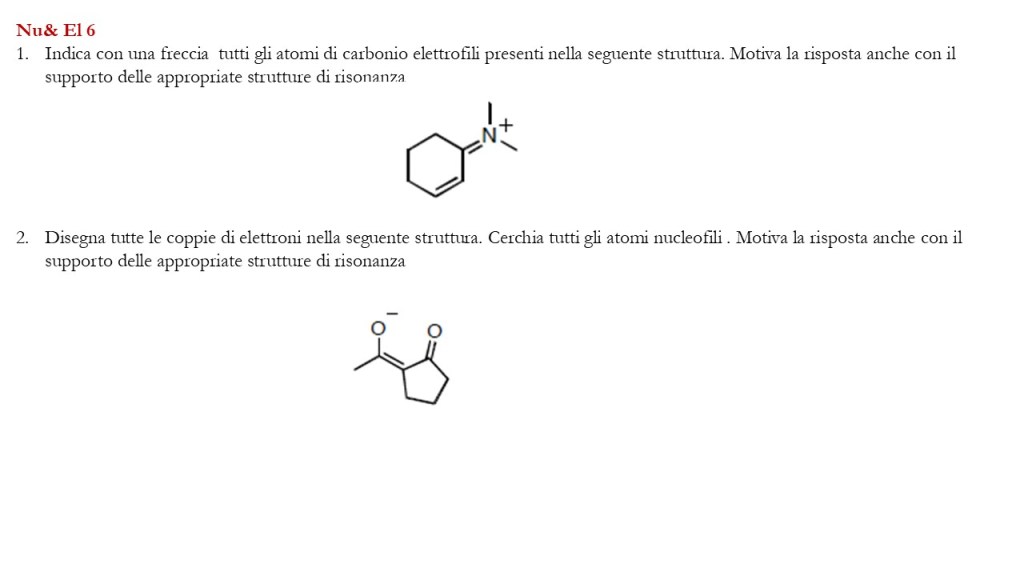
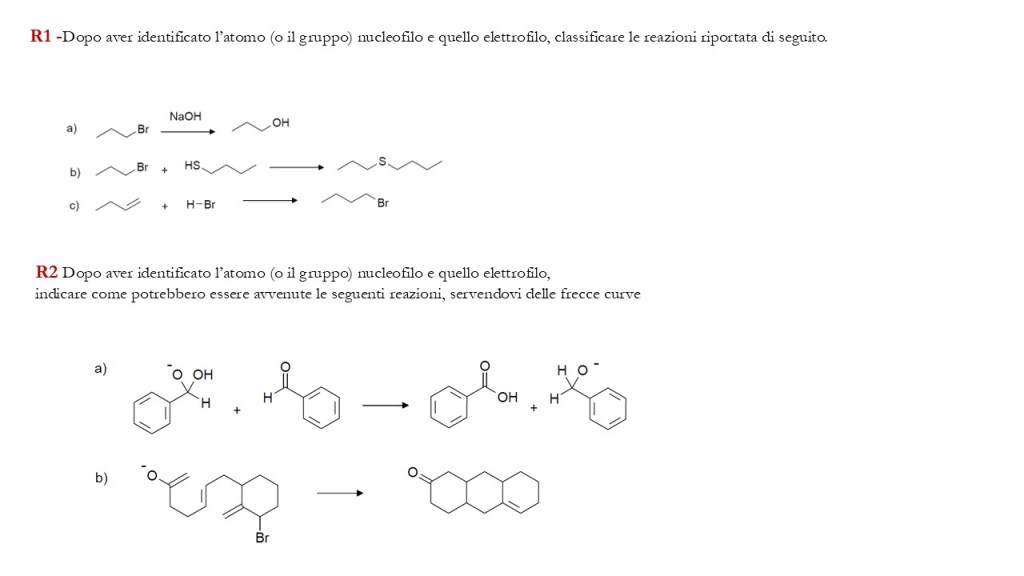
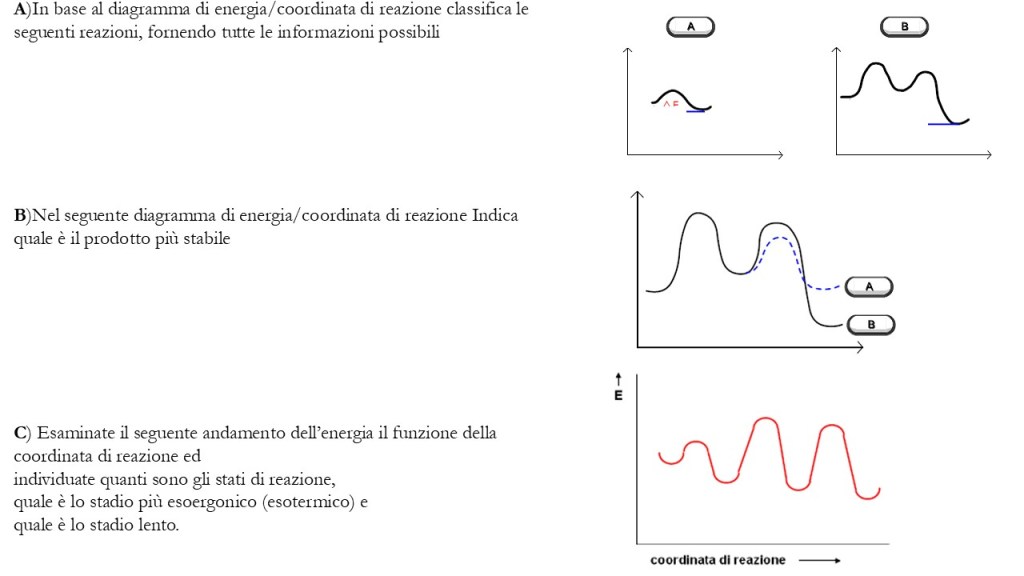
di seguito un set di esercizi inerenti gli argomenti già trattati al corso



You must be logged in to post a comment.